Title here
Summary here

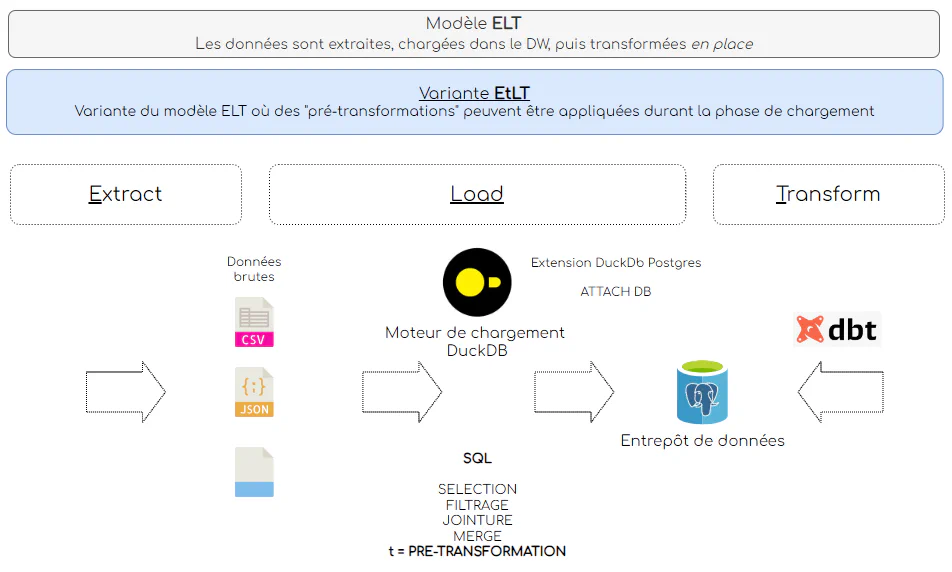
DuckDB est un système de gestion de base de données analytiques (OLAP - Online Analytical Processing) en mémoire, conçu pour l’analyse de données à haute vitesse.
Il est portable, léger, et facile d’installation. Il peut être utilisé via une interface de ligne de commande (DuckDB CLI), disponible sous Windows, Linux et MacOS, ou via des API disponibles pour differents langage dont Python, ce qui permet de l’embarquer dans des workflow de données comme moteur d’execution de calcul.
Le périmètre d’utilisation de DuckDB est comparable à celui de librairies comme Pandas, mais avec des performances bien supérieures, ce qui en fait plutôt une alternative orientée SQL à la librairie Polars.
Une des forces de DuckDB est sa capacité à requêter en SQL directement à partir des fichiers de données CSV, Parquet, JSON comme s’il s’agissait de tables de bases de données (voir démo plus bas).
Même si DuckDB permet de persister les données dans un fichier, le stockage des données transformées pour constituer une datawarehouse n’est pas sa vocation première.
Nous utilisons donc le SGBD PostgreSQL comme entrepôt de données, et DuckDB comme moteur de chargement via son extension PostgreSQL.
Les scripts Python de chargement utilisent l’API Client Python de DuckDB qui offre les mêmes possibilités que la CLI DuckDB.
Nous effectons certaines pré-transformations à partir des fichiers de données brutes avant de les charger dans l’entrepôt de données:
Ex1: pour la source COG CARTO, nous calculons les centres géographiques (les centroides), afin de valoriser un attribut latitude et longitude pour chaque territoire.
Ex2: pour les établissements SIRENE, le fichier est voulumineux, et nous n’utiliserons que 2 colonnes sur les 53 disponibles, et env. 16M de lignes sur les 38M présentes dans le fichier. Le pré-traitement nous permet ici d’economiser en charge de calcul et de stockage.
Afin de démontrer la puissance de DuckDB, nous allons effectuer quelques manipulations sur le fichier CSV Stock Etablissement Sirene utilisé dans ce projet. Caractèristiques du fichier: 8G sur disque, 38 910 206 enregistrements de 53 colonnes.
En seulement 5s DuckDB va nous permettre de:
Filtrer les 38M d’enregistrements sur les colonnes etatAdministratifEtablissement et activitePrincipaleEtablissement afin de ne conserver ques les établissements actifs du secteur de l’ingénierie logicielle
Sélectionner uniquement les 2 colonnes qui nous interressent
Exporter le résultat dans un nouveau fichier CSV ne pesant plus que 4.6M
# Téléchargement et décompactage DuckDB CLI...
wget https://github.com/duckdb/duckdb/releases/download/v1.0.0/duckdb_cli-linux-amd64.zip
unzip duckdb_cli-linux-amd64.zip
# Télechargement et décompactage Stock Etablissement Sirene depuis data.gouv...
wget -O etablissement.zip https://www.data.gouv.fr/fr/datasets/r/0651fb76-bcf3-4f6a-a38d-bc04fa708576
unzip etablissement.zip
# Lancement du moteur DuckDB
./duckdb
v1.0.0 1f98600c2c
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
# Activation du timer via Dot Command
D .timer on
# La Dot Command .shell nous permet de lancer des commandes SHELL depuis la CLI DuckDB
# Notre fichier pèse 8G sur disque
D .shell ls -lh
total 11G
-rw-r--r-- 1 root root 8.0G Aug 1 06:58 StockEtablissement_utf8.csv
-rwxr-xr-x 1 root root 44M May 30 11:07 duckdb
-rw-r--r-- 1 root root 2.4G Aug 1 08:50 etablissement.zip
# Notre fichier contient 38 910 206 lignes
D SELECT COUNT(*) FROM 'StockEtablissement_utf8.csv';
100% ▕████████████████████████████████████████████████████████████▏
┌──────────────┐
│ count_star() │
│ int64 │
├──────────────┤
│ 38910206 │
└──────────────┘
Run Time (s): real 5.606 user 22.982446 sys 3.417665
# Notre fichier contient 53 colonnes. La commande DESCRIBE nous donne le format des colonnes inféré par DuckDB.
D DESCRIBE FROM 'StockEtablissement_utf8.csv';
┌────────────────────────────────────────────────┬─────────────┬─────────┬─────────┬─────────┬─────────┐
│ column_name │ column_type │ null │ key │ default │ extra │
│ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │
├────────────────────────────────────────────────┼─────────────┼─────────┼─────────┼─────────┼─────────┤
│ siren │ VARCHAR │ YES │ │ │ │
│ nic │ VARCHAR │ YES │ │ │ │
│ siret │ VARCHAR │ YES │ │ │ │
│ statutDiffusionEtablissement │ VARCHAR │ YES │ │ │ │
│ dateCreationEtablissement │ DATE │ YES │ │ │ │
│ trancheEffectifsEtablissement │ VARCHAR │ YES │ │ │ │
│ anneeEffectifsEtablissement │ BIGINT │ YES │ │ │ │
│ activitePrincipaleRegistreMetiersEtablissement │ VARCHAR │ YES │ │ │ │
│ dateDernierTraitementEtablissement │ TIMESTAMP │ YES │ │ │ │
│ etablissementSiege │ BOOLEAN │ YES │ │ │ │
│ nombrePeriodesEtablissement │ BIGINT │ YES │ │ │ │
│ complementAdresseEtablissement │ VARCHAR │ YES │ │ │ │
│ numeroVoieEtablissement │ VARCHAR │ YES │ │ │ │
│ indiceRepetitionEtablissement │ VARCHAR │ YES │ │ │ │
│ dernierNumeroVoieEtablissement │ VARCHAR │ YES │ │ │ │
│ indiceRepetitionDernierNumeroVoieEtablissement │ VARCHAR │ YES │ │ │ │
│ typeVoieEtablissement │ VARCHAR │ YES │ │ │ │
│ libelleVoieEtablissement │ VARCHAR │ YES │ │ │ │
│ codePostalEtablissement │ VARCHAR │ YES │ │ │ │
│ libelleCommuneEtablissement │ VARCHAR │ YES │ │ │ │
│ · │ · │ · │ · │ · │ · │
│ · │ · │ · │ · │ · │ · │
│ · │ · │ · │ · │ · │ · │
│ typeVoie2Etablissement │ VARCHAR │ YES │ │ │ │
│ libelleVoie2Etablissement │ VARCHAR │ YES │ │ │ │
│ codePostal2Etablissement │ VARCHAR │ YES │ │ │ │
│ libelleCommune2Etablissement │ VARCHAR │ YES │ │ │ │
│ libelleCommuneEtranger2Etablissement │ VARCHAR │ YES │ │ │ │
│ distributionSpeciale2Etablissement │ VARCHAR │ YES │ │ │ │
│ codeCommune2Etablissement │ VARCHAR │ YES │ │ │ │
│ codeCedex2Etablissement │ VARCHAR │ YES │ │ │ │
│ libelleCedex2Etablissement │ VARCHAR │ YES │ │ │ │
│ codePaysEtranger2Etablissement │ VARCHAR │ YES │ │ │ │
│ libellePaysEtranger2Etablissement │ VARCHAR │ YES │ │ │ │
│ dateDebut │ DATE │ YES │ │ │ │
│ etatAdministratifEtablissement │ VARCHAR │ YES │ │ │ │
│ enseigne1Etablissement │ VARCHAR │ YES │ │ │ │
│ enseigne2Etablissement │ VARCHAR │ YES │ │ │ │
│ enseigne3Etablissement │ VARCHAR │ YES │ │ │ │
│ denominationUsuelleEtablissement │ VARCHAR │ YES │ │ │ │
│ activitePrincipaleEtablissement │ VARCHAR │ YES │ │ │ │
│ nomenclatureActivitePrincipaleEtablissement │ VARCHAR │ YES │ │ │ │
│ caractereEmployeurEtablissement │ VARCHAR │ YES │ │ │ │
├────────────────────────────────────────────────┴─────────────┴─────────┴─────────┴─────────┴─────────┤
│ 53 rows (40 shown) 6 columns │
└──────────────────────────────────────────────────────────────────────────────────────────────────────┘
Run Time (s): real 0.080 user 0.056260 sys 0.023407
# Nous ne souhaitons garder que les établissement actifs (etatAdministratifEtablissement = 'A'), soit 15M de lignes sur les 38M du fichier.
D SELECT
etatAdministratifEtablissement,
COUNT(*) AS nombre
FROM
'StockEtablissement_utf8.csv'
GROUP BY
etatAdministratifEtablissement;
100% ▕████████████████████████████████████████████████████████████▏
┌────────────────────────────────┬──────────┐
│ etatAdministratifEtablissement │ nombre │
│ varchar │ int64 │
├────────────────────────────────┼──────────┤
│ A │ 15871413 │
│ F │ 23038793 │
└────────────────────────────────┴──────────┘
Run Time (s): real 5.512 user 24.144687 sys 3.199846
# Filtrage, selection et export CSV en seulement 5.610 sur un fichier de 8G et 38M de lignes
D COPY (
SELECT
'2024-08' AS version,
e.codeCommuneEtablissement,
e.activitePrincipaleEtablissement
FROM
'StockEtablissement_utf8.csv' AS e
WHERE
e.etatAdministratifEtablissement = 'A'
AND
e.activitePrincipaleEtablissement IN ('62.01Z','62.02A','62.02B')
) TO 'sirene-ingenierie-logicielle_2024-08.csv' (HEADER, DELIMITER ',');
100% ▕████████████████████████████████████████████████████████████▏
Run Time (s): real 5.610 user 24.964715 sys 3.199701
D .shell ls -lh
total 11G
-rw-r--r-- 1 root root 8.0G Aug 1 06:58 StockEtablissement_utf8.csv
-rwxr-xr-x 1 root root 44M May 30 11:07 duckdb
-rw-r--r-- 1 root root 2.4G Aug 1 08:50 etablissement.zip
-rw-r--r-- 1 root root 4.6M Aug 1 12:21 sirene-ingenierie-logicielle_2024-08.csv
# Affichage de l'aperçu de l'export
D .shell head -10 sirene-ingenierie-logicielle_2024-08.csv
version,codeCommuneEtablissement,activitePrincipaleEtablissement
2024-08,97605,62.02A
2024-08,97611,62.02B
2024-08,97611,62.01Z
2024-08,97608,62.01Z
2024-08,13204,62.01Z
2024-08,13210,62.01Z
2024-08,97611,62.02A
2024-08,97611,62.02B
2024-08,67482,62.02A
D .quit
# Et voilà !Le traitement de chargement des offres d’emploi est executé via le script Python /chargement/chargement_offres.py
Il comporte deux fonctions:
chargement_offres_date(date_creation): pré-transformation et chargement d’un unique fichier JSON d’offres.
chargement_offres_stock(): pré-transformation et chargement de l’ensemble des fichiers JSON d’offres présents dans le dossier /donnees_brutes/offre_emploi.
def chargement_offres_stock():
"""
offres-*.json: nous indiquons à DuckDB de prendre l'ensemble des fichiers JSON d'offres présents dans le dossier de stockage des données brutes.
DuckDB permet en effet de traiter un ensemble de fichiers de même format et même schéma comme une unique source en entrée.
"""
file_path = os.path.join(os.getenv('DESTINATION_OFFRE_EMPLOI'), 'offres-*.json')
with duckdb.connect() as con:
"""
Les deux commandes suivantes charge l'extension PostgreSQL.
L'extension PostgreSQL permet à DuckDB de lire et écrire directement depuis une instance de base de données Postgres.
"""
con.install_extension("postgres")
con.load_extension("postgres")
"""
La commande ATTACH permet d'ajouter une connexion vers l'instance Postgres, accessible à DuckDB via l'alias de connexion 'entrepot'
"""
con.sql("ATTACH 'dbname=entrepot user=entrepot password=entrepot host=entrepot' AS entrepot (TYPE POSTGRES);")
"""
Pré-transformation puis chargement:
___________________________________________________________________________________________________________________
- conversion de format: il peut arriver qu'un système de base de données interprète mal un format de données.
Les attributs dateCreation et qualificationCode sont convertis explicitement.
- filtrage des attributs chargés dans l'entrepôt (nous chargons uniquement les attributs dont nous avons besoin)
"""
SQL = f"""
CREATE OR REPLACE TABLE entrepot.offre_emploi AS (
SELECT
id,
CAST(dateCreation AS DATE) AS date_creation,
lieuTravail.commune AS lieu_travail_code,
lieuTravail.latitude AS lieu_travail_latitude,
lieuTravail.longitude AS lieu_travail_longitude,
codeNAF AS code_naf,
romeCode AS code_rome,
entreprise.entrepriseAdaptee AS entreprise_adaptee,
typeContrat AS type_contrat,
natureContrat AS nature_contrat,
experienceExige AS experience_exige,
alternance AS alternance,
nombrePostes AS nombre_postes,
accessibleTH AS accessible_TH,
CAST(qualificationCode AS VARCHAR) AS qualification_code
FROM
'{file_path}'
)
"""
con.sql(SQL)
con.execute("SELECT COUNT(*) FROM entrepot.offre_emploi")
print(f"\n\n{con.fetchone()[0]} enregistrements chargés !\n\n")Le traitement de chargement GOG CARTO est executé via le script Python /chargement/chargement_cog_carto.py.
Il traite les fichiers Shapefile Région, Département, Commune, Arrondissement municipal et effectue les opérations suivantes:
Sélection des métadonnées des fichiers.
Export des géométries dans des fichiers au format GeoJSON, pour les visualisations spatiales des données.
Calcule les centres géographiques.
Charge les métadonnées et les centres géographiques calculés dans l’entrepôt.
Les métadonnées des niveaux Commune et Arrondissement municipal contiennent également la population.
ls -lh
total 119M
-rw-r--r-- 1 root root 5 Mar 19 09:29 COMMUNE.cpg
-rw-r--r-- 1 root root 6.6M Mar 19 09:29 COMMUNE.dbf # fichier de métadonnées
-rw-r--r-- 1 root root 145 Mar 19 09:29 COMMUNE.prj
-rw-r--r-- 1 root root 112M Mar 19 09:29 COMMUNE.shp # fichier contenant les géométries
-rw-r--r-- 1 root root 274K Mar 19 09:29 COMMUNE.shx
# DuckDB permet de lire les fichiers Shapefile grâce à son extentiel spatial
./duckdb
v1.0.0 1f98600c2c
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
D INSTALL spatial;
D LOAD spatial;
D .timer on
D DESCRIBE FROM 'COG/COMMUNE.shp';
┌─────────────┬─────────────┬─────────┬─────────┬─────────┬─────────┐
│ column_name │ column_type │ null │ key │ default │ extra │
│ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │
├─────────────┼─────────────┼─────────┼─────────┼─────────┼─────────┤
│ ID │ VARCHAR │ YES │ │ │ │
│ NOM │ VARCHAR │ YES │ │ │ │
│ NOM_M │ VARCHAR │ YES │ │ │ │
│ INSEE_COM │ VARCHAR │ YES │ │ │ │
│ STATUT │ VARCHAR │ YES │ │ │ │
│ POPULATION │ INTEGER │ YES │ │ │ │
│ INSEE_CAN │ VARCHAR │ YES │ │ │ │
│ INSEE_ARR │ VARCHAR │ YES │ │ │ │
│ INSEE_DEP │ VARCHAR │ YES │ │ │ │
│ INSEE_REG │ VARCHAR │ YES │ │ │ │
│ SIREN_EPCI │ VARCHAR │ YES │ │ │ │
│ geom │ GEOMETRY │ YES │ │ │ │
├─────────────┴─────────────┴─────────┴─────────┴─────────┴─────────┤
│ 12 rows 6 columns │
└───────────────────────────────────────────────────────────────────┘
Run Time (s): real 0.003 user 0.001133 sys 0.000137...
con.install_extension("postgres")
con.load_extension("postgres")
con.sql("ATTACH 'dbname=entrepot user=entrepot password=entrepot host=entrepot' AS entrepot (TYPE POSTGRES);")
con.install_extension("spatial")
con.load_extension("spatial")
...
"""
Export de certaines métadonnées et de la géométrie dans un fichier GeoJSON departement-metropole.geojson
"""
# Chemin vers le fichier Shapefile dans le répertoire des données brutes
shp_departement=f"{os.path.join(os.getenv('DESTINATION_COG_CARTO'),version,'DEPARTEMENT.shp')}"
# Chemin d'export du fichier GeoJSON
geojson_file_path = os.path.join('/visualisation', 'departement-metropole.geojson')
SQL = f"""
COPY (
SELECT
shp.insee_dep,
shp.nom,
shp.geom
FROM
'{shp_departement}' AS shp
WHERE
shp.insee_reg NOT IN ('01','02','03','04','06')
)
TO '{geojson_file_path}'
WITH (FORMAT GDAL, DRIVER 'GeoJSON', LAYER_CREATION_OPTIONS 'WRITE_BBOX=YES')
"""
con.sql(SQL)Aperçu d’un fichier geojson généré
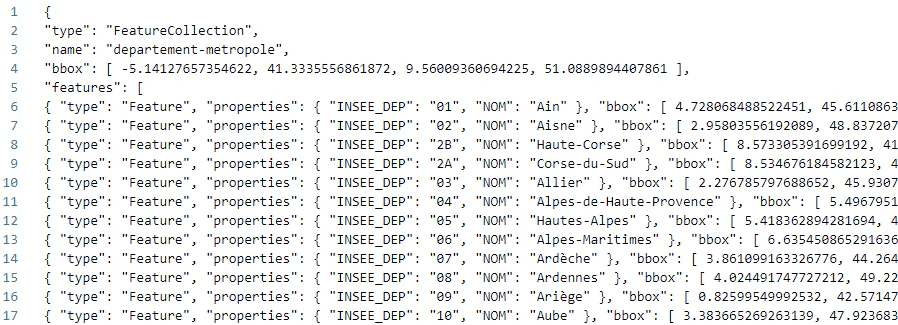
Les contours géographiques sont représentés sous forme d’ensemble de points formant des Polygon ou des MultiPolygon

"""
ST_X(ST_Centroid(shp.geom)) AS long: calcul du centroide de la géométrie et extraction de la composante longitude
ST_Y(ST_Centroid(shp.geom)) AS lat: calcul du centroide de la géométrie et extraction de la composante latitude
"""
con.sql( f"""
CREATE OR REPLACE TABLE entrepot.cog_carto_departement AS (
SELECT
'{version}' AS version,
shp.insee_dep,
shp.insee_reg,
shp.nom,
ST_X(ST_Centroid(shp.geom)) AS long,
ST_Y(ST_Centroid(shp.geom)) AS lat
FROM
'{shp_departement}' AS shp
)
"""import os
import duckdb
from zipfile import ZipFile
def decompactage(yyyy_mm):
nom_archive=f"{os.getenv('DESTINATION_SIRENE')}/etablissements_sirene_{yyyy_mm}.zip"
with ZipFile(nom_archive, 'r') as f:
f.extractall(path=os.getenv('DESTINATION_SIRENE'))
def chargement(yyyy_mm):
csv=f"{os.path.join(os.getenv('DESTINATION_SIRENE'),'StockEtablissement_utf8.csv')}"
with duckdb.connect() as con:
con.install_extension("postgres")
con.load_extension("postgres")
con.sql("ATTACH 'dbname=entrepot user=entrepot password=entrepot host=entrepot' AS entrepot (TYPE POSTGRES);")
SQL = f"""
CREATE OR REPLACE TABLE entrepot.sirene_etablissement AS (
SELECT
'{yyyy_mm}' AS version,
e.codeCommuneEtablissement,
e.activitePrincipaleEtablissement
FROM
'{csv}' AS e
WHERE
e.etatAdministratifEtablissement = 'A'
)
"""
con.sql(SQL)
con.execute("SELECT COUNT(*) FROM entrepot.sirene_etablissement")
print(f"\n\n{con.fetchone()[0]} enregistrements chargés !\n\n")
os.remove(csv)Extrait:
# Niveau 1
con.sql( f"""
CREATE OR REPLACE TABLE entrepot.naf2008_liste_n1 AS (
SELECT
*
FROM
'{os.getenv('DESTINATION_NAF')}/naf2008_liste_n1.csv'
)
"""