Title here
Summary here
Pour pouvoir utiliser les API, il est nécessaire de:
Créer un compte sur la plateforme francetravail.io et s’authentifier
Déplarer une application. Un identifiant client et une clé secrète sont alors générés par la plateforme, permettant d’authentifier les requêtes sur les API
Ajouter les API utilisées par l’application déclarée
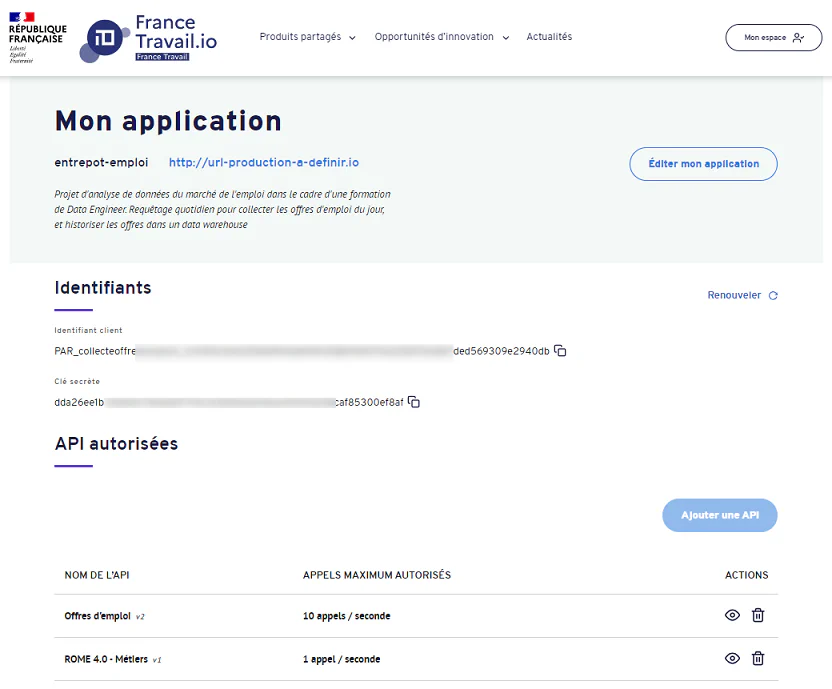
Les appels d’API doivent être authentifiés via un Bearer Token placé dans le header HTTP Authorization
Ce token est obtenu via une requête de génération d’un access token, en fournissant les paramètres client_id et client_secret obtenus lors de la création d’une application sur la plateforme.
Exemple de réponse à une requête de génération d’un access token:
{
"access_token": "rJEr40urkiEHRl4wjuvlcWqdzGE",
"scope": "api_offresdemploiv2 o2dsoffre",
"token_type": "Bearer",
"expires_in": 1499
}{
"id": "string",
"intitule": "string",
"description": "string",
"dateCreation": "2019-08-24T14:15:22Z",
"dateActualisation": "2019-08-24T14:15:22Z",
"lieuTravail": {
"libelle": "string",
"latitude": 0,
"longitude": 0,
"codePostal": "string",
"commune": "string"
},
"romeCode": "string",
"romeLibelle": "string",
"appellationlibelle": "string",
"entreprise": {
"nom": "string",
"description": "string",
"logo": "string",
"url": "string",
"entrepriseAdaptee": true
},
"typeContrat": "string",
"typeContratLibelle": "string",
"natureContrat": "string",
"experienceExige": "string",
"experienceLibelle": "string",
"experienceCommentaire": "string",
"formations": [
{
"codeFormation": "string",
"domaineLibelle": "string",
"niveauLibelle": "string",
"commentaire": "string",
"exigence": "string"
}
],
"langues": [
{
"libelle": "string",
"exigence": "string"
}
],
"permis": [
{
"libelle": "string",
"exigence": "string"
}
],
"outilsBureautiques": [
"string"
],
"competences": [
{
"code": "string",
"libelle": "string",
"exigence": "string"
}
],
"salaire": {
"libelle": "string",
"commentaire": "string",
"complement1": "string",
"complement2": "string"
},
"dureeTravailLibelle": "string",
"dureeTravailLibelleConverti": "string",
"complementExercice": "string",
"conditionExercice": "string",
"alternance": true,
"contact": {
"nom": "string",
"coordonnees1": "string",
"coordonnees2": "string",
"coordonnees3": "string",
"telephone": "string",
"courriel": "string",
"commentaire": "string",
"urlRecruteur": "string",
"urlPostulation": "string"
},
"agence": {
"telephone": "string",
"courriel": "string"
},
"nombrePostes": -2147483648,
"accessibleTH": true,
"deplacementCode": "string",
"deplacementLibelle": "string",
"qualificationCode": "string",
"qualificationLibelle": "string",
"codeNAF": "string",
"secteurActivite": "string",
"secteurActiviteLibelle": "string",
"qualitesProfessionnelles": [
{
"libelle": "string",
"description": "string"
}
],
"trancheEffectifEtab": "string",
"origineOffre": {
"origine": "string",
"urlOrigine": "string",
"partenaires": [
{
"nom": "string",
"url": "string",
"logo": "string"
}
]
},
"offresManqueCandidats": true
}Le endpoint /partenaire/offresdemploi/v2/offres/search permet une recherche d’offres selon certains critères
Nous souhaitons collecter quotidiennement l’ensemble des offres créées à une date donnée, pour cela nous utilisons les critères minCreationDate et maxCreationDate
La plage de résultats des requêtes est limitée à 150 par l’API. Autrement dit, on peut collecter un maximum de 150 offres par requête.
Pour pouvoir collecter l’ensemble des offres repondant à nos critères de recherche (minCreationDate et maxCreationDate pour notre cas d’usage), il est nécessaire d’utiliser la pagination des données ou fenêtrage, en fournissant le paramètre range=p-d, où:
p est l’index (débutant à 0) du premier élément demandé ne devant pas dépasser 3000.
d est l’index de dernier élément demandé ne devant pas dépasser 3149.
range=p-d signifie que l’on souhaite obtenir les offres dont l’index est situé dans l’interval allant de p jusqu’à d.
NB: si le nombre d’offres indiqué dans l’interval est supérieur à 150, l’API retournera un status code 400 Bad Request et la réponse ci-dessous:
{
"message": "La plage de résultats demandée est trop importante.",
"codeHttp": 400,
"codeErreur": "1722445850117"
}curl \
--request GET \
--url 'https://api.francetravail.io/partenaire/offresdemploi/v2/offres/search?range=0-149&minCreationDate=2024-07-29T00:00:00Z&maxCreationDate=2024-07-30T00:00:00Z' \
--header 'Accept: application/json' \
--header 'Authorization: Bearer {token}'L’API nous renvoie alors les 150 premières offres de résultats (range=0-149)
Un response header HTTP Content-Range=offres 0-149/15262 nous indique que les offres retournées sont les offres d’indices 0 à 149, sur un total de 15 262 offres correspondants à nos critères de recherche.
Pour collecter les 150 offres suivantes, nous executerons la même requête avec le paramètre range=150-300, et le header Content-Range de la réponse HTTP vaudra alors Content-Range=offres 150-300/15262.
Attention
L’index de dernier élément demandé d spécifié dans le paramètre range ne peut être supérieur à 3149. De cette manière, nous ne pourrons collecter que 3148 offres sur un total de 15 262 résultats.
Autrement dit …
Pour une recherche d’offres donnée, c’est à dire correspondant à un ensemble de critères de recherche spécifiés, le nombre d’offres qu’il est possible de collecter sera limité à 3148.
Il est donc nécessaire, à chaque fois qu’une recherche d’offres retourne plus de 3148 résultats, d’itérer les offres en ajoutant des critères de recherche supplémentaires de sorte que le nombre de résultats rétournés soit toujours en déça du maximum autorisé.
Difficulté supplémentaire: tous les attributs d’une offre ne sont pas systématiquement valorisés. Une offre dont tel attribut n’est pas valorisé ne sera pas retournée par une requête filtrant sur cet attribut.
Après de multiples test, la stratégie que nous avons retenue est la suivante:
Itération des offres pour une date de création donnée (minCreationDate/maxCreationDate) et pour chaque code ROME de la nomenclature ROME.
Si le nombre d’offres pour une date de création et un code Rome donnés est supérieur à 3148, on itère ces offres (Date création / Code ROME) sur chaque région de localisation de l’offre.
Le traitement de collecte des offres d’emploi est executé via le script Python /collecte/collecte_offres.py
Ce script est executé executé tous les jours à 01h00 via Apache Airflow pour collecter les offres créées la veille.
Les offres collectées sont stockées dans le dossier /donnees_brutes/offre_emploi
Pour chaque execution quotidienne, deux fichiers sont créés:
offres-{YYY-MM-dd}.json: ensemble des offres créées à une date donnée. Taille moyenne des fichiers: 150 MB.
offres-{YYY-MM-dd}.log: métriques d’execution du traitement (nombre offres collecte, durée).
Ex: offres-2024-05-21.log
{
"dt_deb_collecte": "24/05/2024 16:08:57",
"date_creation": "2024-05-21",
"dt_fin_collecte": "24/05/2024 16:13:39",
"total_offres": 49969,
"total_offres_collecte": 49969,
"duree_totale": "00:04"
}La durée d’execution du script est d’environ 4 min pour en moyenne 40 000 offres créées quotidiennement.
L’API offre d’emploi expose également le endpoint /partenaire/offresdemploi/v2/referentiel/, permettant d’obtenir les référentiels utilisés par les variables catégorielles d’une offre d’emploi.
Le script de collecte télécharge les référentiels Appelations ROME et Régions afin de pouvoir itérer les offres sur les codes ROME et les codes région.
Liste des référentiels de l’API Offres d’emploi
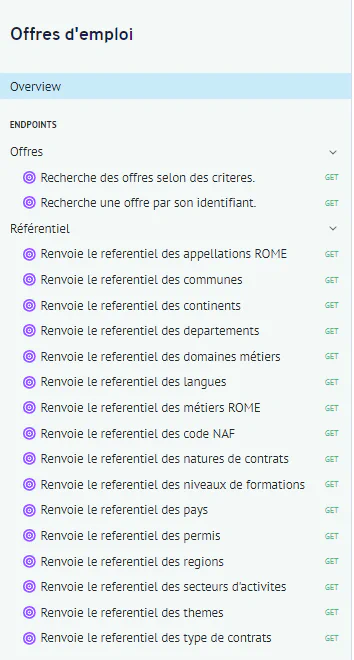
Nous souhaitons pouvoir comptabiliser les offres d’emploi par métier.
En fonction des cas d’usage, nous souhaitons pouvoir effectuer ces calculs au niveau le plus fin, un métier donné, ou à un niveau plus général (Grand domaine ou famille de métiers).
Le référentiel Appelations ROME de l’API offres d’emploi ne comporte que le niveau le plus fin, le niveau métier. Il nous faut donc utilisée l’API dédiée ROME 4.0 - Métiers de francetravail.io pour collecter les 3 niveaux de la nomenclature ROME.
Le traitement de collecte de la nomenclature ROME est executé via le script Python /collecte/collecte_rome.py
Les offres collectées sont stockées dans le dossier /donnees_brutes/rome dans 3 fichiers distincts:
domaine_professionnel.json
grand_domaine.json
metier.json
Les 3 niveaux seront dénormalisés par le traitement de chargement.
Cette nomenclature évoluant peu, le traitement de collecte est executé une fois, lors de l’initialisation.
Les URL’s de téléchargement sont disponibles ici
La version utilisée pour ce projet est ADMIN-EXPRESS-COG-CARTO édition 2024 France entière du 22/02/2024
En analysant le format de l’URL de téléchargement:
Attribut population
https://data.geopf.fr/telechargement/download/ADMIN-EXPRESS-COG-CARTO/ADMIN-EXPRESS-COG-CARTO_3-2__SHP_WGS84G_FRA_2024-02-22/ADMIN-EXPRESS-COG-CARTO_3-2__SHP_WGS84G_FRA_2024-02-22.7z)
, on constate que son format peut être généralisé sous la forme:
Attribut population
https://data.geopf.fr/telechargement/download/ADMIN-EXPRESS-COG-CARTO/ADMIN-EXPRESS-COG-CARTO_3-2__SHP_WGS84G_FRA_{VERSION_COG_CARTO}/ADMIN-EXPRESS-COG-CARTO_3-2__SHP_WGS84G_FRA_{VERSION_COG_CARTO}.7z
Un paramètre de configuration VERSION_COG_CARTO=2024-02-22 passé en tant que variable d’environnement via le fichier .env du projet permet de rendre paramètrable la version à télécharger.
Le traitement de collecte consiste à télécharger une archive au format 7z, de décompacter l’archive et d’extraire de l’arborescence du dossier décompacté uniquement les fichiers Shapefile dont nous avons besoin.
Le traitement de collecte du jeu de données COG_CARTO est executé via le script Python /collecte/collecte_cog_carto.py
Les fichiers collectées sont stockées dans le dossier /donnees_brutes/cog_carto.
Le traitement comporte 3 étapes executées par des tâches Airflow distinctes:
Téléchargement de l’archive
Décompactage
Recherche dans l’arborescence du dossier décompactés les fichiers Shapefile et déplacement dans un sous-dossier nommé {YYYY-MM-DD}, correspond à la version du jeu de données. Ce sous-dossier sera supprimé à l’issu du traitement de chargement, seul le fichier d’archive compacté sera conservé dans le dossier donnees_brutes/cog_carto.
Le traitement de collecte du jeu de données StockEtablissement est executé via le script Python /collecte/collecte_sirene.py
Le fichier collecté est stocké dans le dossier /donnees_brutes/sirene.
Le traitement télécharge le fichier d’archive vers le fichier /donnees_brutes/sirene/etablissements_sirene_{YYYY-MM}.zip, où {YYYY-MM} correspond à l’année et au mois calculé à partir le la date d’execution du traitement.
Le décompactage extrait le fichier CSV à l’emplacement /donnees_brutes/sirene/StockEtablissement_utf8.csv. Ce fichier, volumineux, sera supprimé à l’issu du traitement de chargement, et le fichier d’archive compacté conservé afin de passer l’étape de téléchargement si le traitement est executé plusiers fois au cours du même mois.
L’URL de téléchargement correspond à l’URL stable indiquée sur la plateforme data.gouv
Récupération de l’URL de téléchargement sur la plateforme data.gouv:
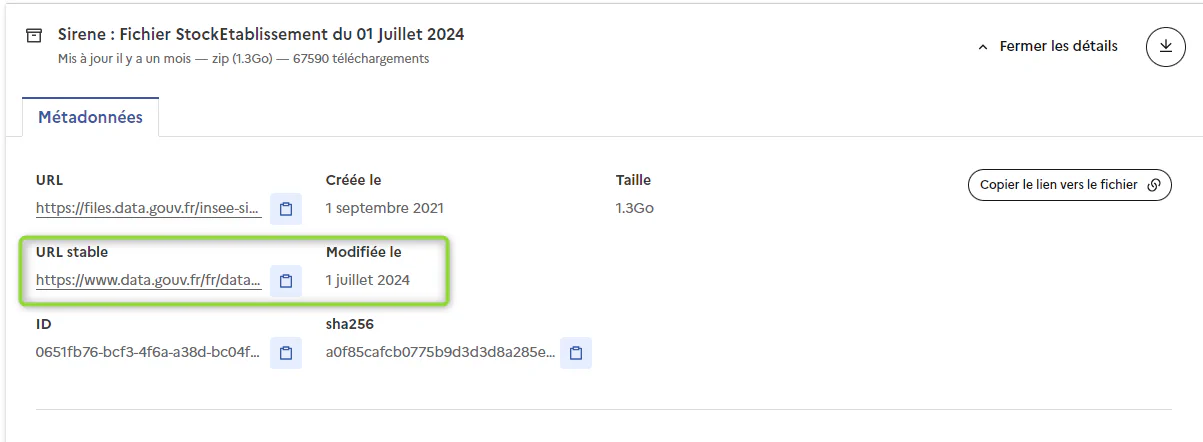
Pour ce jeu de données, les opérations sont effectuées manuellement, cette nomenclature n’évoluant que très rarement (dernière évolution en 2008)
L’INSEE met à disposition sur son site une page dédiée permettant de télécharger au format Excel les 5 niveaux de la nomenclature, ainsi qu’un fichier de correspondance entre les diférents niveaux
Les opérations manuelles suivantes ont été réalisées pour chaque fichier:
Téléchargement du fichier Excel
Modifications mineures du fichier pour le rendre compatible au format CSV (suppression des lignes inutiles en haut de la feuille principalement)
Export au format CSV
Le dossier /donnees_brutes/naf contient alors les fichiers suivants:
naf2008_5_niveaux.csv: fichier de correspondance entre les diférents niveaux
naf2008_liste_n1.csv: sections
naf2008_liste_n2.csv: divisions
naf2008_liste_n3.csv: groupes
naf2008_liste_n4.csv: classes
naf2008_liste_n5.csv: sous-classes
Les 5 niveaux seront dénormalisés par le traitement de chargement.