Title here
Summary here
L’objectif de ce projet était de produire un entrepôt de données et une analyse des données d’offres d’emploi de France Travail, au travers de tableaux de bord de visualisation de données.
En collectant quotidiennement les nouvelles offres d’emploi, nous serons en capacité à terme d’analyser l’évolution du marché de l’emploi en France au cours du temps, et tenter d’en dégager des tendances.
Pour ce faire, nous collectons également d’autres jeux de données issus de l’Open Data pour les croiser avec les offres d’emploi et ainsi enrichir les données d’offres d’emploi.
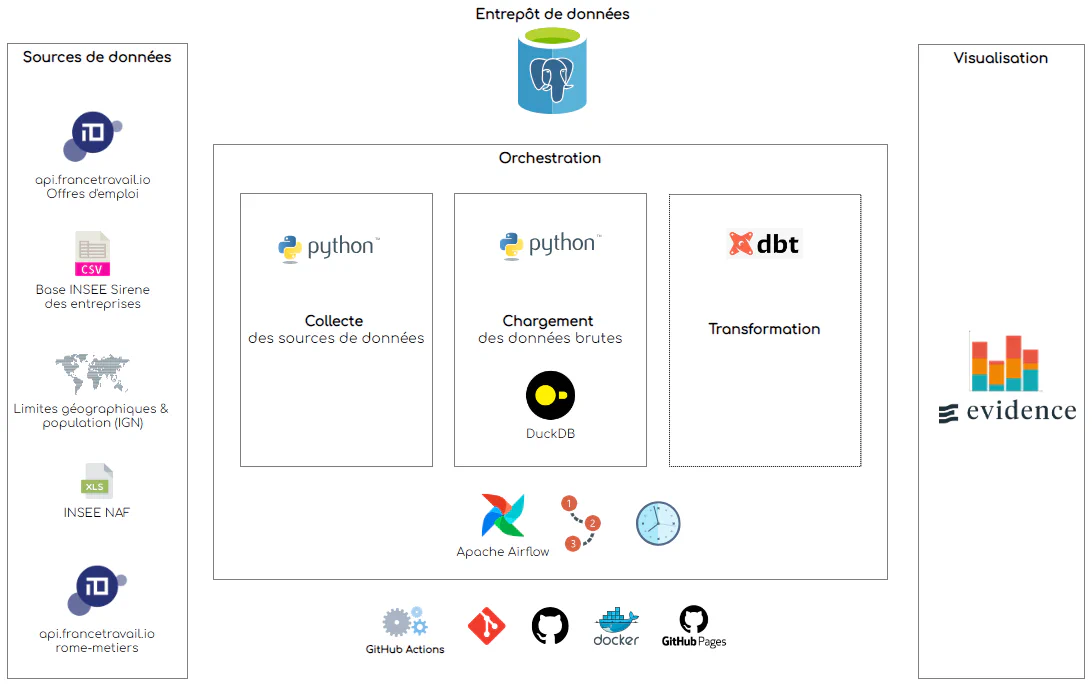
Notre objectif pour ce projet était d’adopter une approche Modern Data Stack, consistant en l’utilisation de technologies et de pratiques modernes pour collecter, charger, transformer et analyser les données de manière efficace et évolutive. A ce titre, nous avons fait le choix de technologies Open Source et de pratiques ayant émergées assez récemment:
DuckDB comme moteur de calcul et de chargement pour ses performances, sa facilité d’installation et d’utilisation, sa capacité à lire un grand nombre de format de fichiers, et enfin son approche SQL.
dbt pour la transformation des données brutes et la construction de l’entrepôt de données, en SQL également, et avec une approche ELT versus ETL.
evidence pour la partie visualisation des données, qui permet de produire des sites statiques à partir de fichier Markdown, et qui utilise également DuckDB dans sa version WebAssembly comme moteur de stockage interne.
A partir des jeux de données sources, des scripts Python collectent les données dans des fichiers de données brutes à l’emplacement /donnees_brutes du projet.
Des scripts Python chargent les données brutes à partir des fichiers de collecte dans l’entrepôt de données PostgreSQL.
Les données brutes chargées dans l’entrepôt sont transformées via dbt pour construire l’entrepôt de données cible dans un schéma de base de données nommé emploi.
Enfin, evidence extrait les données de l’entrepôt dans des fichiers Parquet, qu’il charge ensuite via son moteur interne DuckDB WASM pour afficher les visualisations de données.
L’ensemble des traitements permettant de construire l’entrepôt de données sont executés, programmés et ordonnancés avec Apache Airflow.