Title here
Summary here
Apache Airflow, développé en Python, dispose d’un opérateur PythonOperator, qui peut aussi être implémenté via un décorateur @task appliqué à une fonction Python. Il peut alors être tentant d’écrire directement nos fonctions Python dans les DAG Airflow. Cependant, ceci ne constitue pas une bonne pratique car cela créé une adhérence vis à vis d’Airflow.
En effet, on pourrait très bien décider de revenir sur le choix d’Airflow comme outil d’ordonnancement, et nous souhaitons que nos traitement soient indépendants d’Airflow, afin de rendre une telle migration plus simple.
Les scripts Python de collecte et de chargement sont rendus accesibles à Airflow via des modules de fonctions, via un fichier __init__.py dans les dossiers /collecte et /chargement.
Les modules de code sont mappés dans les conteneurs Airflow dans le dossier /opt/airflow/modules, et cet emplacement indiqué à Airflow via la variable PYTHONPATH
Extrait du fichier docker-compose.yml
x-airflow-common:
&airflow-common
build: ./airflow
user: "${AIRFLOW_UID:-50000}:${AIRFLOW_GID:-50000}"
environment:
&airflow-common-env
...
# L'emplacement /opt/airflow/modules est rendu accessible à Airflow via la variable PYTHONPATH
PYTHONPATH: /opt/airflow/modules:$PYTHONPATH
...
volumes:
...
# Les modules de code sont copiés dans un dossier /opt/airflow/modules des conteneurs Airflow
- ./collecte:/opt/airflow/modules/collecte
- ./chargement:/opt/airflow/modules/chargement
- ./transformation:/opt/airflow/modules/transformation
- ./visualisation/static:/visualisation
...Extrait du DAG initialisation:
from datetime import datetime, timedelta
import pendulum
import os
import pendulum
from airflow.decorators import dag, task
from airflow.operators.bash import BashOperator
from airflow.utils.task_group import TaskGroup
from airflow.decorators import dag, task
"""
Import des modules de fonctions Python utilisés dans les tâches Airflow
"""
from chargement import chargement_cog_carto, chargement_naf, chargement_rome, chargement_sirene, chargement_offres
from collecte import collecte_rome, collecte_sirene, collecte_offres, collecte_cog_carto
local_tz = pendulum.timezone("Europe/Paris")
@dag(
dag_id='initialisation',
description='Chargement dans entrepôt DuckDB nomenclature NAF',
schedule=None,
start_date=datetime(2024, 5, 23, tzinfo=local_tz),
catchup=False
)
def initialisation():
"""
PythonOperator faisant appel à une fonction Python du module chargement
"""
@task
def nomenclature_naf():
chargement_naf.chargement()
with TaskGroup("cog_carto") as cog_carto:
@task
def telechargement():
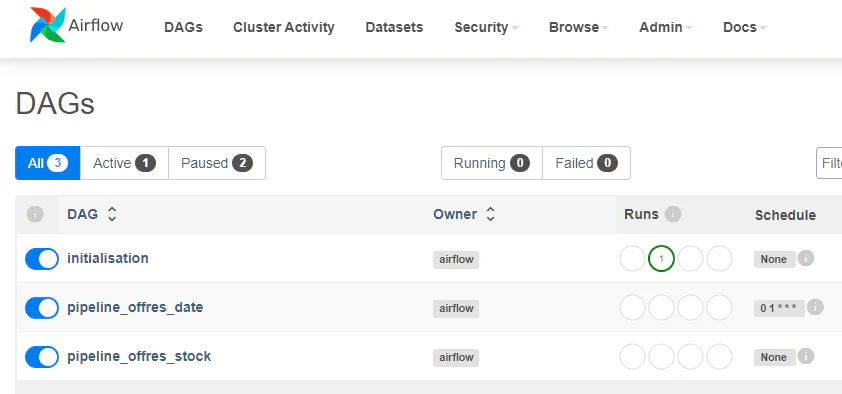
collecte_cog_carto.telechargement()initialisation: l’execution de ce DAG n’est pas programmé. Il doit être executé manuellement pour initialiser le projet. Il execute l’ensemble des tâches nécessaires à la visualisation des données, de la collecte à la transformation des données et la contruction de l’entrepôt de données.
pipeline_offres_date: ce DAG est programmé tous les jours à 01h00 ( 0 1 * * * ), et collecte et charge dans l’entrepôt les offres d’emploi créées la veille.
pipeline_offres_stock: l’execution de ce DAG n’est pas programmé. Il doit être executé manuellement pour charger un ensemble de fichiers de collecte d’offres présents dans le dossier /donnees/brutes/offre_emploi.
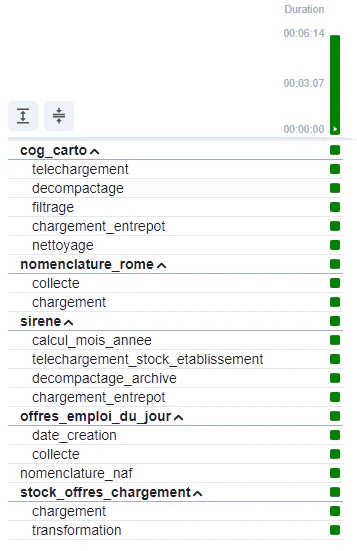
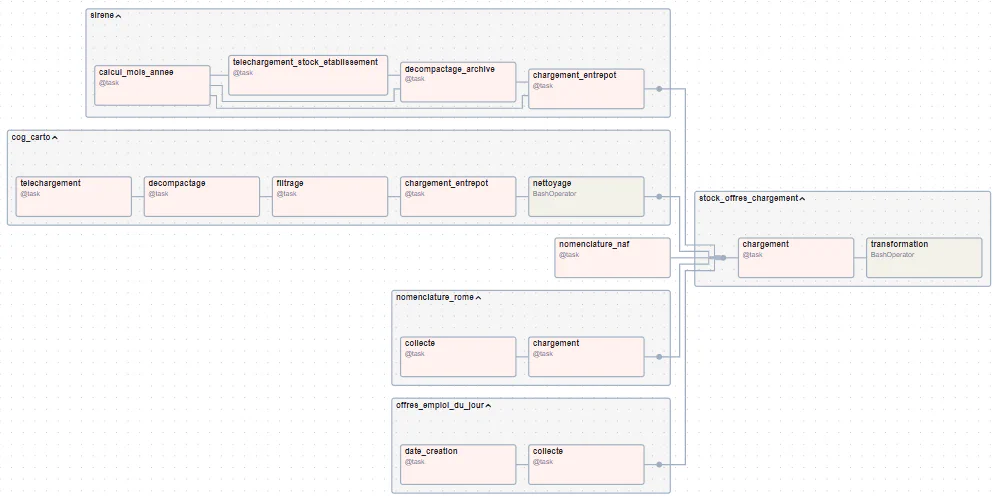
TaskGroup sont implémentés pour améliorer la lisibilité du pipeline et faciliter l’écriture des dépendanceswith TaskGroup("nomenclature_rome") as nomenclature_rome:
@task
def collecte():
collecte_rome.collecte()
@task
def chargement():
chargement_rome.chargement()
collecte() >> chargement()
...
"""
Ordonnancement des TaskGroup et des tâches
L'execution des differents TaskGroup est parallèlisée grâce à la notation [], puis le TaskGroup stock_offres_chargement est executé.
"""
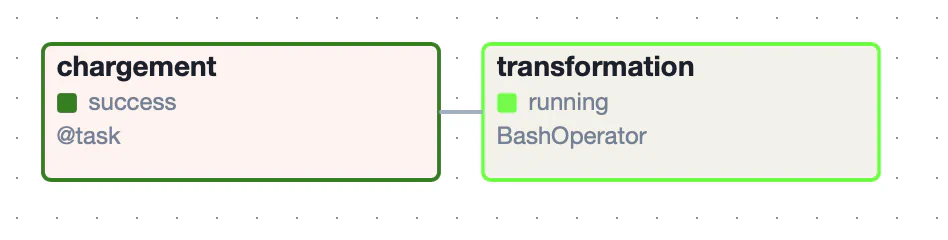
[nomenclature_naf(), cog_carto, nomenclature_rome, sirene, offres_emploi_du_jour] >> stock_offres_chargementoffres-YYYY-MM-DD.jsondbt run --target prod via un BashOperator dans le dossier /opt/airflow/modules/transformation monté via un volume Docker.

from datetime import datetime, timedelta
import pendulum
from airflow.decorators import dag, task
from airflow.operators.bash import BashOperator
from collecte import collecte_offres
from chargement import chargement_offres
local_tz = pendulum.timezone("Europe/Paris")
"""
Tous les jours à 01h00, requêtage api des offres créées J-1, puis chargement
"""
@dag(
dag_id='pipeline_offres_date',
description='Collecte des offres créées J-1',
schedule_interval='0 1 * * *',
start_date=datetime(2024, 5, 23, tzinfo=local_tz),
catchup=False
)
def pipeline_offres_date():
@task
def date_creation(ds):
return (datetime.strptime(ds, '%Y-%m-%d') + timedelta(days=-1)).strftime('%Y-%m-%d')
@task
def collecte(date_creation):
collecte_offres.collecte_offres_date(date_creation=date_creation)
@task
def chargement(date_creation):
chargement_offres.chargement_offres_date(date_creation=date_creation)
transformation = BashOperator(
task_id='transformation',
bash_command="""
cd /opt/airflow/modules/transformation
dbt run --target prod
"""
)
_date_creation = date_creation()
collecte(date_creation=_date_creation) >> chargement(date_creation=_date_creation) >> transformation
pipeline_offres_date()Extraits des logs d’execution Airflow. Tâche collecte: détails du parcours des offres
[2024-08-04, 11:21:20 CEST] {logging_mixin.py:188} INFO -
04/08/2024 11:21:20: démarrage collecte de 50175 offres d'emploi depuis francetravail.io
[2024-08-04, 11:21:20 CEST] {logging_mixin.py:188} INFO - A1407: 9
[2024-08-04, 11:21:20 CEST] {logging_mixin.py:188} INFO - A1408: 2
[2024-08-04, 11:21:21 CEST] {logging_mixin.py:188} INFO - A1409: 9
[2024-08-04, 11:21:21 CEST] {logging_mixin.py:188} INFO - A1410: 1
[2024-08-04, 11:21:21 CEST] {logging_mixin.py:188} INFO - A1411: 5
[2024-08-04, 11:21:21 CEST] {logging_mixin.py:188} INFO - A1412: 2
[2024-08-04, 11:21:22 CEST] {logging_mixin.py:188} INFO - A1504: 20
...
[2024-08-04, 11:25:28 CEST] {logging_mixin.py:188} INFO - B1605: 2
[2024-08-04, 11:25:29 CEST] {logging_mixin.py:188} INFO - G1211: 0
[2024-08-04, 11:25:29 CEST] {logging_mixin.py:188} INFO - A1102: 5
[2024-08-04, 11:25:29 CEST] {logging_mixin.py:188} INFO - A1304: 22
..
[2024-08-04, 11:25:34 CEST] {logging_mixin.py:188} INFO - J1308: 4
[2024-08-04, 11:25:34 CEST] {logging_mixin.py:188} INFO - J1309: 5
[2024-08-04, 11:25:35 CEST] {logging_mixin.py:188} INFO - K1306: 2905
[2024-08-04, 11:25:43 CEST] {logging_mixin.py:188} INFO - D1410: 161
[2024-08-04, 11:25:44 CEST] {logging_mixin.py:188} INFO - D1510: 12
[2024-08-04, 11:25:44 CEST] {logging_mixin.py:188} INFO - E1109: 10
[2024-08-04, 11:25:44 CEST] {logging_mixin.py:188} INFO - F1111: 39
[2024-08-04, 11:25:44 CEST] {logging_mixin.py:188} INFO - F1112: 58
Fin collecte de 50171/50175 offres en date du 2024-08-01Extraits des logs d’execution Airflow. Tâche chargement
946ac78f5af0
*** Found local files:
*** * /opt/airflow/logs/dag_id=pipeline_offres_date/run_id=scheduled__2024-08-02T23:00:00+00:00/task_id=chargement/attempt=1.log
[2024-08-04, 11:25:59 CEST] {local_task_job_runner.py:120} ▶ Pre task execution logs
[2024-08-04, 11:26:01 CEST] {logging_mixin.py:188} INFO -
50171 enregistrements chargés !
[2024-08-04, 11:26:01 CEST] {python.py:237} INFO - Done. Returned value was: None
[2024-08-04, 11:26:01 CEST] {taskinstance.py:441} ▶ Post task execution logsExtraits des logs d’execution Airflow. Tâche transformation
946ac78f5af0
*** Found local files:
*** * /opt/airflow/logs/dag_id=pipeline_offres_date/run_id=scheduled__2024-08-02T23:00:00+00:00/task_id=transformation/attempt=1.log
[2024-08-04, 11:26:02 CEST] {local_task_job_runner.py:120} ▶ Pre task execution logs
[2024-08-04, 11:26:02 CEST] {subprocess.py:63} INFO - Tmp dir root location: /tmp
[2024-08-04, 11:26:02 CEST] {subprocess.py:75} INFO - Running command: ['/usr/bin/bash', '-c', '\n cd /opt/***/modules/transformation\n dbt run --target prod\n ']
[2024-08-04, 11:26:02 CEST] {subprocess.py:86} INFO - Output:
[2024-08-04, 11:26:04 CEST] {subprocess.py:93} INFO - 09:26:04 Running with dbt=1.8.4
[2024-08-04, 11:26:05 CEST] {subprocess.py:93} INFO - 09:26:05 Registered adapter: postgres=1.8.2
[2024-08-04, 11:26:05 CEST] {subprocess.py:93} INFO - 09:26:05 Found 7 models, 15 sources, 417 macros
[2024-08-04, 11:26:05 CEST] {subprocess.py:93} INFO - 09:26:05
[2024-08-04, 11:26:05 CEST] {subprocess.py:93} INFO - 09:26:05 Concurrency: 4 threads (target='prod')
[2024-08-04, 11:26:05 CEST] {subprocess.py:93} INFO - 09:26:05
[2024-08-04, 11:26:05 CEST] {subprocess.py:93} INFO - 09:26:05 1 of 7 START sql incremental model emploi.departement .......................... [RUN]
[2024-08-04, 11:26:05 CEST] {subprocess.py:93} INFO - 09:26:05 2 of 7 START sql incremental model emploi.dim_lieu ............................. [RUN]
[2024-08-04, 11:26:05 CEST] {subprocess.py:93} INFO - 09:26:05 3 of 7 START sql table model emploi.dim_lieu_activite .......................... [RUN]
[2024-08-04, 11:26:05 CEST] {subprocess.py:93} INFO - 09:26:05 4 of 7 START sql table model emploi.dim_naf .................................... [RUN]
[2024-08-04, 11:26:05 CEST] {subprocess.py:93} INFO - 09:26:05 4 of 7 OK created sql table model emploi.dim_naf ............................... [SELECT 732 in 0.29s]
[2024-08-04, 11:26:05 CEST] {subprocess.py:93} INFO - 09:26:05 5 of 7 START sql incremental model emploi.dim_rome ............................. [RUN]
[2024-08-04, 11:26:05 CEST] {subprocess.py:93} INFO - 09:26:05 1 of 7 OK created sql incremental model emploi.departement ..................... [INSERT 0 101 in 0.31s]
[2024-08-04, 11:26:05 CEST] {subprocess.py:93} INFO - 09:26:05 6 of 7 START sql incremental model emploi.fait_offre_emploi .................... [RUN]
[2024-08-04, 11:26:06 CEST] {subprocess.py:93} INFO - 09:26:06 2 of 7 OK created sql incremental model emploi.dim_lieu ........................ [INSERT 0 34980 in 0.46s]
[2024-08-04, 11:26:06 CEST] {subprocess.py:93} INFO - 09:26:06 5 of 7 OK created sql incremental model emploi.dim_rome ........................ [INSERT 0 609 in 0.15s]
[2024-08-04, 11:26:06 CEST] {subprocess.py:93} INFO - 09:26:06 7 of 7 START sql table model emploi.region ..................................... [RUN]
[2024-08-04, 11:26:06 CEST] {subprocess.py:93} INFO - 09:26:06 7 of 7 OK created sql table model emploi.region ................................ [SELECT 18 in 0.08s]
[2024-08-04, 11:26:06 CEST] {subprocess.py:93} INFO - 09:26:06 6 of 7 OK created sql incremental model emploi.fait_offre_emploi ............... [INSERT 0 50171 in 0.66s]
[2024-08-04, 11:26:15 CEST] {subprocess.py:93} INFO - 09:26:15 3 of 7 OK created sql table model emploi.dim_lieu_activite ..................... [SELECT 2550627 in 9.41s]
[2024-08-04, 11:26:15 CEST] {subprocess.py:93} INFO - 09:26:15
[2024-08-04, 11:26:15 CEST] {subprocess.py:93} INFO - 09:26:15 Finished running 3 table models, 4 incremental models in 0 hours 0 minutes and 9.57 seconds (9.57s).
[2024-08-04, 11:26:15 CEST] {subprocess.py:93} INFO - 09:26:15
[2024-08-04, 11:26:15 CEST] {subprocess.py:93} INFO - 09:26:15 Completed successfully
[2024-08-04, 11:26:15 CEST] {subprocess.py:93} INFO - 09:26:15
[2024-08-04, 11:26:15 CEST] {subprocess.py:93} INFO - 09:26:15 Done. PASS=7 WARN=0 ERROR=0 SKIP=0 TOTAL=7
[2024-08-04, 11:26:16 CEST] {subprocess.py:97} INFO - Command exited with return code 0
[2024-08-04, 11:26:16 CEST] {taskinstance.py:441} ▶ Post task execution logsdbt run --target prod via un BashOperator dans le dossier /opt/airflow/modules/transformation monté via un volume Docker.
from datetime import datetime, timedelta
import pendulum
from airflow.decorators import dag, task
from airflow.operators.bash import BashOperator
from chargement import chargement_offres
local_tz = pendulum.timezone("Europe/Paris")
"""
Chargement et transformation du stock de fichiers brutes d'offres présents dans le dossier donnees_brutes.
"""
@dag(
dag_id="pipeline_offres_stock",
description="Chargement et transformation du stock de fichiers brutes d'offres présents dans le dossier donnees_brutes.",
schedule=None,
start_date=datetime(2024, 5, 23, tzinfo=local_tz),
catchup=False
)
def pipeline_offres_stock():
@task
def chargement():
chargement_offres.chargement_offres_stock()
transformation = BashOperator(
task_id='transformation',
bash_command="""
cd /opt/airflow/modules/transformation
dbt run --target prod
"""
)
chargement() >> transformation
pipeline_offres_stock()Extraits des logs d’execution Airflow. Tâche chargement
1b5a09019707
*** Found local files:
*** * /opt/airflow/logs/dag_id=pipeline_offres_stock/run_id=manual__2024-08-05T12:02:19.222433+00:00/task_id=chargement/attempt=1.log
[2024-08-05, 14:02:19 CEST] {local_task_job_runner.py:120} ▼ Pre task execution logs
[2024-08-05, 14:02:19 CEST] {taskinstance.py:2073} INFO - Dependencies all met for dep_context=non-requeueable deps ti=<TaskInstance: pipeline_offres_stock.chargement manual__2024-08-05T12:02:19.222433+00:00 [queued]>
[2024-08-05, 14:02:19 CEST] {taskinstance.py:2073} INFO - Dependencies all met for dep_context=requeueable deps ti=<TaskInstance: pipeline_offres_stock.chargement manual__2024-08-05T12:02:19.222433+00:00 [queued]>
[2024-08-05, 14:02:19 CEST] {taskinstance.py:2303} INFO - Starting attempt 1 of 1
[2024-08-05, 14:02:19 CEST] {taskinstance.py:2327} INFO - Executing <Task(_PythonDecoratedOperator): chargement> on 2024-08-05 12:02:19.222433+00:00
[2024-08-05, 14:02:19 CEST] {standard_task_runner.py:90} INFO - Running: ['***', 'tasks', 'run', 'pipeline_offres_stock', 'chargement', 'manual__2024-08-05T12:02:19.222433+00:00', '--job-id', '32', '--raw', '--subdir', 'DAGS_FOLDER/pipeline_offres_stock.py', '--cfg-path', '/tmp/tmpzxzkhqf7']
[2024-08-05, 14:02:19 CEST] {logging_mixin.py:188} WARNING - /home/***/.local/lib/python3.12/site-packages/***/task/task_runner/standard_task_runner.py:61 DeprecationWarning: This process (pid=5632) is multi-threaded, use of fork() may lead to deadlocks in the child.
[2024-08-05, 14:02:19 CEST] {standard_task_runner.py:91} INFO - Job 32: Subtask chargement
[2024-08-05, 14:02:19 CEST] {standard_task_runner.py:63} INFO - Started process 5643 to run task
[2024-08-05, 14:02:19 CEST] {task_command.py:426} INFO - Running <TaskInstance: pipeline_offres_stock.chargement manual__2024-08-05T12:02:19.222433+00:00 [running]> on host 1b5a09019707
[2024-08-05, 14:02:19 CEST] {taskinstance.py:2644} INFO - Exporting env vars: AIRFLOW_CTX_DAG_OWNER='***' AIRFLOW_CTX_DAG_ID='pipeline_offres_stock' AIRFLOW_CTX_TASK_ID='chargement' AIRFLOW_CTX_EXECUTION_DATE='2024-08-05T12:02:19.222433+00:00' AIRFLOW_CTX_TRY_NUMBER='1' AIRFLOW_CTX_DAG_RUN_ID='manual__2024-08-05T12:02:19.222433+00:00'
[2024-08-05, 14:02:19 CEST] {taskinstance.py:430} ▲▲▲ Log group end
[2024-08-05, 14:02:39 CEST] {logging_mixin.py:188} INFO -
893703 enregistrements chargés !
[2024-08-05, 14:02:39 CEST] {python.py:237} INFO - Done. Returned value was: None
[2024-08-05, 14:02:39 CEST] {taskinstance.py:441} ▼ Post task execution logs
[2024-08-05, 14:02:39 CEST] {taskinstance.py:1205} INFO - Marking task as SUCCESS. dag_id=pipeline_offres_stock, task_id=chargement, execution_date=20240805T120219, start_date=20240805T120219, end_date=20240805T120239
[2024-08-05, 14:02:39 CEST] {local_task_job_runner.py:240} INFO - Task exited with return code 0
[2024-08-05, 14:02:39 CEST] {taskinstance.py:3482} INFO - 1 downstream tasks scheduled from follow-on schedule check
[2024-08-05, 14:02:39 CEST] {local_task_job_runner.py:222} ▲▲▲ Log group endExtraits des logs d’execution Airflow. Tâche transformation
1b5a09019707
*** Found local files:
*** * /opt/airflow/logs/dag_id=pipeline_offres_stock/run_id=manual__2024-08-05T12:02:19.222433+00:00/task_id=transformation/attempt=1.log
[2024-08-05, 14:02:39 CEST] {local_task_job_runner.py:120} ▶ Pre task execution logs
[2024-08-05, 14:02:39 CEST] {subprocess.py:63} INFO - Tmp dir root location: /tmp
[2024-08-05, 14:02:39 CEST] {subprocess.py:75} INFO - Running command: ['/usr/bin/bash', '-c', '\n cd /opt/***/modules/transformation\n dbt run --target prod\n ']
[2024-08-05, 14:02:39 CEST] {subprocess.py:86} INFO - Output:
[2024-08-05, 14:02:41 CEST] {subprocess.py:93} INFO - 12:02:41 Running with dbt=1.8.3
[2024-08-05, 14:02:41 CEST] {subprocess.py:93} INFO - 12:02:41 Registered adapter: postgres=1.8.2
[2024-08-05, 14:02:41 CEST] {subprocess.py:93} INFO - 12:02:41 Found 7 models, 15 sources, 415 macros
[2024-08-05, 14:02:41 CEST] {subprocess.py:93} INFO - 12:02:41
[2024-08-05, 14:02:41 CEST] {subprocess.py:93} INFO - 12:02:41 Concurrency: 4 threads (target='prod')
[2024-08-05, 14:02:41 CEST] {subprocess.py:93} INFO - 12:02:41
[2024-08-05, 14:02:41 CEST] {subprocess.py:93} INFO - 12:02:41 1 of 7 START sql incremental model emploi.departement .......................... [RUN]
[2024-08-05, 14:02:41 CEST] {subprocess.py:93} INFO - 12:02:41 2 of 7 START sql incremental model emploi.dim_lieu ............................. [RUN]
[2024-08-05, 14:02:41 CEST] {subprocess.py:93} INFO - 12:02:41 3 of 7 START sql table model emploi.dim_lieu_activite .......................... [RUN]
[2024-08-05, 14:02:41 CEST] {subprocess.py:93} INFO - 12:02:41 4 of 7 START sql table model emploi.dim_naf .................................... [RUN]
[2024-08-05, 14:02:41 CEST] {subprocess.py:93} INFO - 12:02:41 1 of 7 OK created sql incremental model emploi.departement ..................... [INSERT 0 101 in 0.18s]
[2024-08-05, 14:02:41 CEST] {subprocess.py:93} INFO - 12:02:41 4 of 7 OK created sql table model emploi.dim_naf ............................... [SELECT 732 in 0.18s]
[2024-08-05, 14:02:41 CEST] {subprocess.py:93} INFO - 12:02:41 5 of 7 START sql incremental model emploi.dim_rome ............................. [RUN]
[2024-08-05, 14:02:41 CEST] {subprocess.py:93} INFO - 12:02:41 6 of 7 START sql incremental model emploi.fait_offre_emploi .................... [RUN]
[2024-08-05, 14:02:42 CEST] {subprocess.py:93} INFO - 12:02:42 5 of 7 OK created sql incremental model emploi.dim_rome ........................ [INSERT 0 609 in 0.12s]
[2024-08-05, 14:02:42 CEST] {subprocess.py:93} INFO - 12:02:42 7 of 7 START sql table model emploi.region ..................................... [RUN]
[2024-08-05, 14:02:42 CEST] {subprocess.py:93} INFO - 12:02:42 2 of 7 OK created sql incremental model emploi.dim_lieu ........................ [INSERT 0 34980 in 0.38s]
[2024-08-05, 14:02:42 CEST] {subprocess.py:93} INFO - 12:02:42 7 of 7 OK created sql table model emploi.region ................................ [SELECT 18 in 0.08s]
[2024-08-05, 14:02:47 CEST] {subprocess.py:93} INFO - 12:02:47 6 of 7 OK created sql incremental model emploi.fait_offre_emploi ............... [INSERT 0 893703 in 5.43s]
[2024-08-05, 14:02:51 CEST] {subprocess.py:93} INFO - 12:02:51 3 of 7 OK created sql table model emploi.dim_lieu_activite ..................... [SELECT 2550627 in 9.34s]
[2024-08-05, 14:02:51 CEST] {subprocess.py:93} INFO - 12:02:51
[2024-08-05, 14:02:51 CEST] {subprocess.py:93} INFO - 12:02:51 Finished running 4 incremental models, 3 table models in 0 hours 0 minutes and 9.46 seconds (9.46s).
[2024-08-05, 14:02:51 CEST] {subprocess.py:93} INFO - 12:02:51
[2024-08-05, 14:02:51 CEST] {subprocess.py:93} INFO - 12:02:51 Completed successfully
[2024-08-05, 14:02:51 CEST] {subprocess.py:93} INFO - 12:02:51
[2024-08-05, 14:02:51 CEST] {subprocess.py:93} INFO - 12:02:51 Done. PASS=7 WARN=0 ERROR=0 SKIP=0 TOTAL=7
[2024-08-05, 14:02:52 CEST] {subprocess.py:97} INFO - Command exited with return code 0
[2024-08-05, 14:02:52 CEST] {taskinstance.py:441} ▶ Post task execution logsDocker est une plateforme qui permet de créer, déployer et exécuter des applications à l’intérieur de conteneurs. Cela permet notamment d’isoler les applications ainsi que leurs dépendances. Nous assurons également la portabilité de notre projet entre les environnements de développement et de production.
Pour notre projet, on définit plusieurs services Docker pour exécuter Apache Airflow avec une base de données PostgreSQL, ainsi qu’une base de données supplémentaire pour le stockage des données. Les conteneurs sont configurés pour communiquer entre eux via un réseau Docker commun, et les données sont conservés à l’aide de volumes.
./airflow)airflow-repo :
airflow-scheduler :
x-airflow-common.airflow-repo pour s’assurer que la base de données est disponible avant de démarrer.airflow-webserver :
airflow-repo.entrepot :
entrepot.data-emploi pour permettre la communication entre les différents services.entrepot pour garder une cohérence entre les données de la base de données entrepot.