Title here
Summary here

dbt (Data Build Tool) est un outil open source utilisé pour transformer, organiser et gérer les données dans un entrepôt de données (data warehouse).
DBT et modèle ELT
dbt est l’un des promoteur du modèle ELT désormais largement adopté, où les données sont chargées dans dans l’entrepôt de données, puis transformées en place, par opposition au modèle traditionnel ETL, où les données sont transformées puis chargées dans l’entrepôt.
Dans ce projet, nous utilisons dbt au travers des fonctionnalités suivantes:
Transformation: dbt permet de définir des transformations SQL de manière organisée et réutilisable. Les transformations sont écrites sous forme de requêtes SQL de sélection, et dbt gère leur exécution.
Documentation: dbt permet de génerer un site statique de documentation des transformations et des modèles de données.
Orchestration: dbt organise et orchestre l’exécution des transformations de données, en garantissant que les dépendances entre les différentes étapes sont respectées et que les transformations sont exécutées dans le bon ordre. De la même manière qu’avec Apache Airflow, des DAG (Directed Acyclic Graph) sont générés par DBT en fonction de dépendances entre les modèles de transformation.
dbt-core. Il faut également installer l’adaptateur correspondant à notre base de données, dbt-postgres dans notre cas. On peut installer directement l’adaptateur qui installera aussi dbt-core.python -m pip install dbt-postgres
dbt --version
Core:
- installed: 1.8.4
- latest: 1.8.4 - Up to date!
Plugins:
- postgres: 1.8.2 - Up to date!dbt init <nom_du_projet> initialise un nouveau projetprofiles.yml dans le répertoire .dbt du profil utilisateur local de la machine, et qui contient les informations de connexion.profiles.yml
transformation:
target: dev
outputs:
dev:
type: postgres
host: localhost
user: entrepot
password: change-it
port: 5432
dbname: entrepot
schema: emploi
threads: 4
prod:
type: postgres
host: entrepot
user: entrepot
password: change-it
port: 5432
dbname: entrepot
schema: emploi
threads: 4# Création d'un nouveau projet DBT nommé "transformation"
dbt init transformation
10:57:18 Running with dbt=1.8.4
10:57:18
Your new dbt project "transformation" was created!
...
Happy modeling!
10:57:18 Setting up your profile.
The profile transformation already exists in C:\Users\cyril.ledean\.dbt\profiles.yml. Continue and overwrite it? [y/N]: y
Which database would you like to use?
[1] postgres
(Don't see the one you want? https://docs.getdbt.com/docs/available-adapters)
Enter a number: 1
host (hostname for the instance): localhost
port [5432]:
user (dev username): entrepot
pass (dev password):
dbname (default database that dbt will build objects in): entrepot
schema (default schema that dbt will build objects in): emploi
threads (1 or more) [1]: 4
10:59:04 Profile transformation written to C:\Users\cyril.ledean\.dbt\profiles.yml using target's profile_template.yml and your supplied values. Run 'dbt debug' to validate the connection.cd .\transformation\
# dbt debug permet de tester la connexion à l'entrepôt de données.
dbt debug
11:36:35 Running with dbt=1.8.4
11:36:35 dbt version: 1.8.4
11:36:35 python version: 3.12.4
11:36:35 python path: C:\privé\DE\entrepot-emploi-transformation\.venv\Scripts\python.exe
11:36:35 os info: Windows-10-10.0.19045-SP0
11:36:36 Using profiles dir at C:\Users\cyril.ledean\.dbt
11:36:36 Using profiles.yml file at C:\Users\cyril.ledean\.dbt\profiles.yml
11:36:36 Using dbt_project.yml file at C:\privé\DE\entrepot-emploi-transformation\transformation\dbt_project.yml
11:36:36 adapter type: postgres
11:36:36 adapter version: 1.8.2
11:36:36 Configuration:
11:36:36 profiles.yml file [OK found and valid]
11:36:36 dbt_project.yml file [OK found and valid]
11:36:36 Required dependencies:
11:36:36 - git [OK found]
11:36:36 Connection:
11:36:36 host: localhost
11:36:36 port: 5432
11:36:36 user: entrepot
11:36:36 database: entrepot
11:36:36 schema: emploi
11:36:36 connect_timeout: 10
11:36:36 role: None
11:36:36 search_path: None
11:36:36 keepalives_idle: 0
11:36:36 sslmode: None
11:36:36 sslcert: None
11:36:36 sslkey: None
11:36:36 sslrootcert: None
11:36:36 application_name: dbt
11:36:36 retries: 1
11:36:36 Registered adapter: postgres=1.8.2
11:36:38 Connection test: [OK connection ok]
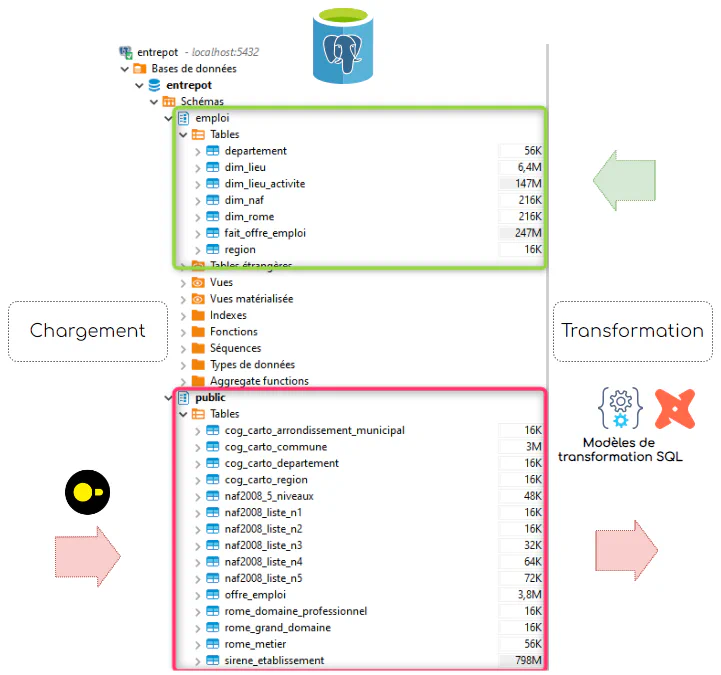
11:36:38 All checks passed!/models: contient les modèles de transformation. Un modèle dbt est une requête SQL de sélection. Cette reqête SQL de sélection sera traduite par dbt run sous forme d’un ordre SQL de création d’une table, vue, ou vue matérialisée. Ce paramètrage s’effectue dans le fichier dbt_project.yml. Un système de templating Jinja permet de faire référence à un modèle à l’intérieur d’un autre modèle. Les contraintes d’antériorité sont analysées par dbt pour générer le graph orienté (DAG).
dbt_project.yml: dans ce fichier nous déclarons nos modèles de transformation, et indiquons via la directive +materialized quel type d’objet de base de donnéees doit être généré. Ici nous générons des tables.
name: 'transformation'
version: '1.0.0'
profile: 'transformation'
model-paths: ["models"]
test-paths: ["tests"]
seed-paths: ["seeds"]
macro-paths: ["macros"]
clean-targets:
- "target"
- "dbt_packages"
models:
transformation:
dim_naf:
+materialized: table
dim_lieu:
+materialized: table
region:
+materialized: table
departement:
+materialized: table
dim_lieu_activite:
+materialized: table
dim_rome:
+materialized: table
fait_offre_emploi:
+materialized: table
Ex: source collecte_naf
version: 2
sources:
# Nous déclarons une source de données nommée collecte_naf
- name: collecte_naf
# Les objets de cette source de données sont situés dans le schéma public de la base de données
schema: public
description: Données brutes nomenclature d’activités française – NAF rév. 2
# Liste des objets de la source et documentation.
tables:
- name: naf2008_5_niveaux
description: Correspondance entre les 5 niveaux de la Nomenclature d’activités française – NAF rév. 2
- name: naf2008_liste_n1
description: Niveau 1 de la nomenclature NAF rév. 2
- name: naf2008_liste_n2
description: Niveau 2 de la nomenclature NAF rév. 2
- name: naf2008_liste_n3
description: Niveau 3 de la nomenclature NAF rév. 2
- name: naf2008_liste_n4
description: Niveau 4 de la nomenclature NAF rév. 2
- name: naf2008_liste_n5
description: Niveau 5 de la nomenclature NAF rév. 2Aperçu de la documentation dbt générée par ce paramètrage:
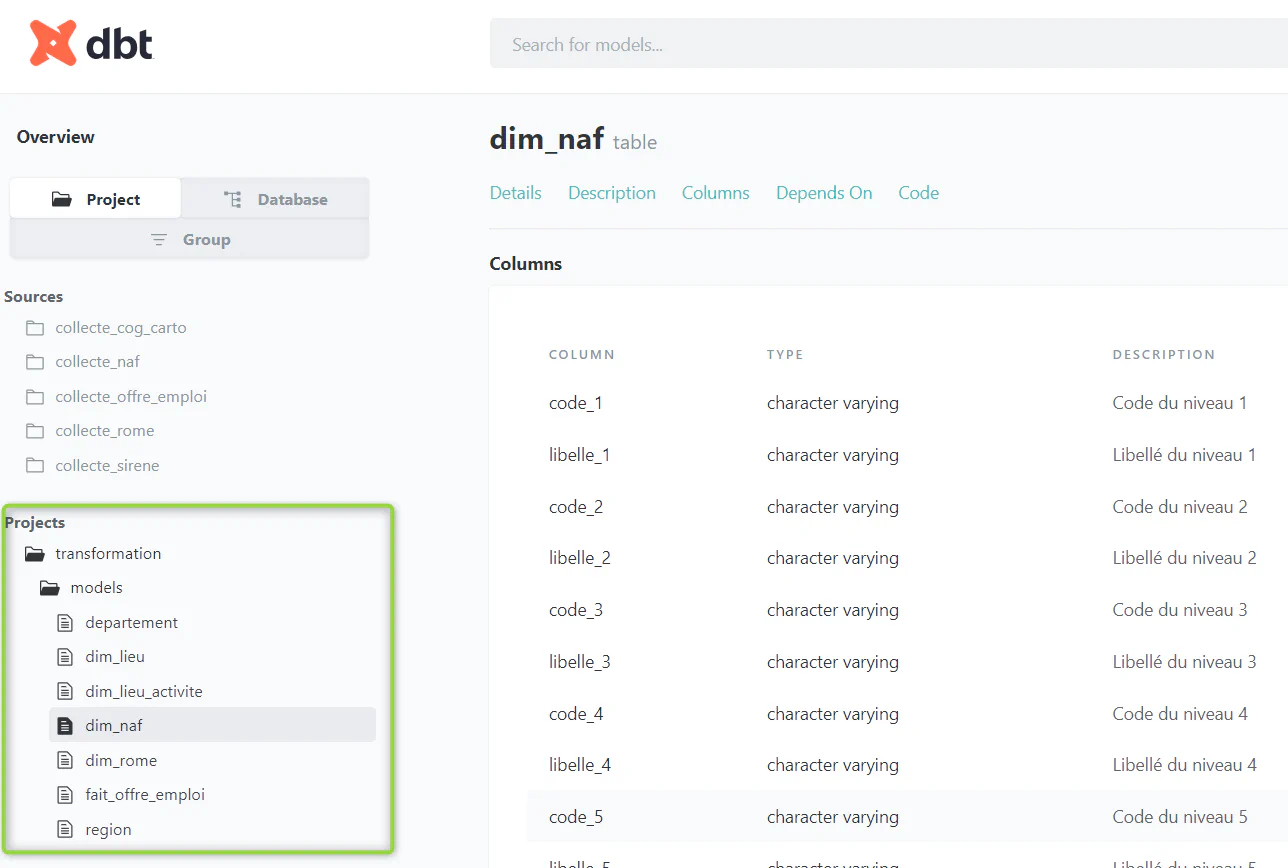
Ex: documentation du modèle dim_naf
models:
- name: dim_naf
description: Dimension activité NAF
columns:
- name: code_1
description: Code du niveau 1
- name: libelle_1
description: Libellé du niveau 1
- name: code_2
description: Code du niveau 2
- name: libelle_2
description: Libellé du niveau 2
- name: code_3
description: Code du niveau 3
- name: libelle_3
description: Libellé du niveau 3
- name: code_4
description: Code du niveau 4
- name: libelle_4
description: Libellé du niveau 4
- name: code_5
description: Code du niveau 5
- name: libelle_5
description: Libellé du niveau 5Aperçu de la documentation dbt générée par ce paramètrage:
--
-- models/dim_naf.sql
--
WITH
hierarchie AS (
SELECT
niv1,
niv2,
niv3,
niv4,
niv5
FROM
{{ source('collecte_naf', 'naf2008_5_niveaux') }}
),
niveau_1 AS (
SELECT
code,
libelle
FROM
{{ source('collecte_naf', 'naf2008_liste_n1') }}
),
niveau_2 AS (
SELECT
code,
libelle
FROM
{{ source('collecte_naf', 'naf2008_liste_n2') }}
),
niveau_3 AS (
SELECT
code,
libelle
FROM
{{ source('collecte_naf', 'naf2008_liste_n3') }}
),
niveau_4 AS (
SELECT
code,
libelle
FROM
{{ source('collecte_naf', 'naf2008_liste_n4') }}
),
niveau_5 AS (
SELECT
code,
libelle
FROM
{{ source('collecte_naf', 'naf2008_liste_n5') }}
)
SELECT
niveau_1.code AS code_1,
niveau_1.libelle AS libelle_1,
niveau_2.code AS code_2,
niveau_2.libelle AS libelle_2,
niveau_3.code AS code_3,
niveau_3.libelle AS libelle_3,
niveau_4.code AS code_4,
niveau_4.libelle AS libelle_4,
niveau_5.code AS code_5,
niveau_5.libelle AS libelle_5
FROM
hierarchie
JOIN
niveau_1 ON hierarchie.niv1 = niveau_1.code
JOIN
niveau_2 ON hierarchie.niv2 = niveau_2.code
JOIN
niveau_3 ON hierarchie.niv3 = niveau_3.code
JOIN
niveau_4 ON hierarchie.niv4 = niveau_4.code
JOIN
niveau_5 ON hierarchie.niv5 = niveau_5.codeDé-normalisation des données
La dénormalisation est une technique de conception de base de données utilisée pour:
Ex: Quelle est l’activité des entreprises qui proposent des emplois de Data Engineer (M1811) ?
select
o.code_naf, naf.libelle_5, count(*) as nombre
from
emploi.fait_offre_emploi as o
join
emploi.dim_naf as naf
on
o.code_naf = naf.code_5
where
o.code_rome = 'M1811'
group by
o.code_naf, naf.libelle_5
order by
count(*) desc;Extrait des résultats retournés par la requête ci-dessus:
| code_naf | libelle_5 | nombre |
|---|---|---|
| 78.20Z | Activités des agences de travail temporaire | 31 |
| 62.02A | Conseil en systèmes et logiciels informatiques | 13 |
| 78.10Z | Activités des agences de placement de main-d’œuvre | 13 |
| 62.01Z | Programmation informatique | 10 |
| 70.10Z | Activités des sièges sociaux | 5 |
| 86.10Z | Activités hospitalières | 5 |
| 71.12B | Ingénierie, études techniques | 4 |
| 70.22Z | Conseil pour les affaires et autres conseils de gestion | 4 |
| 35.11Z | Production d’électricité | 4 |
| … | … | … |
On juge que le niveau de détail est trop fin. Nous souhaitons plutôt agréger les données sur le niveau le plus général, les grandes familes d’activité. Cette modification n’implique qu’une modification mineure de la requête, au niveau des clauses select et group by afin d’agréger sur le niveau 1.
select
naf.code_1, naf.libelle_1, count(*) as nombre
from
emploi.fait_offre_emploi as o
join
emploi.dim_naf as naf
on
o.code_naf = naf.code_5
where
o.code_rome = 'M1811'
group by
naf.code_1, naf.libelle_1
order by
count(*) desc;| code_1 | libelle_1 | nombre |
|---|---|---|
| N | Activités de services administratifs et de soutien | 48 |
| J | Information et communication | 32 |
| M | Activités spécialisées, scientifiques et techniques | 18 |
| C | Industrie manufacturière | 14 |
| K | Activités financières et d’assurance | 8 |
| O | Administration publique | 7 |
| G | Commerce ; réparation d’automobiles et de motocycles | 5 |
| Q | Santé humaine et action sociale | 5 |
| H | Transports et entreposage | 4 |
| D | Production et distribution d’électricité, de gaz, de vapeur et d’air conditionné | 4 |
| P | Enseignement | 3 |
| U | Activités extra-territoriales | 2 |
| E | Production et distribution d’eau ; assainissement, gestion des déchets et dépollution | 1 |
| S | Autres activités de services | 1 |
| B | Industries extractives | 1 |
Graph du modèle dim_dim généré par la documentation dbt:

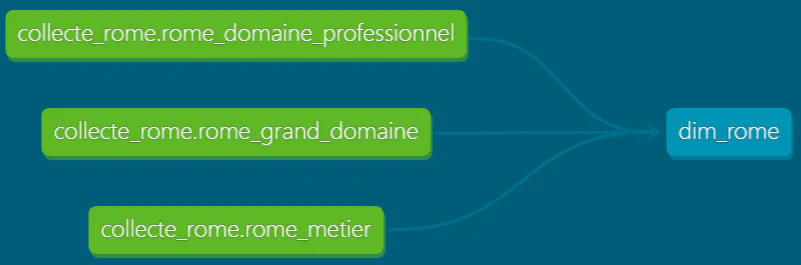
Aperçu de la table dim_rome générée par dbt run:
| code_3 | libelle_3 | code_2 | libelle_2 | code_1 | libelle_1 |
|---|---|---|---|---|---|
| M1405 | Data scientist | M14 | Organisation et études | M | Support à l’entreprise |
| M1811 | Data engineer | M18 | Systèmes d’information et de télécommunication | M | Support à l’entreprise |
| M1812 | Responsable de la Sécurité des Systèmes d’Information (RSSI) | M18 | Systèmes d’information et de télécommunication | M | Support à l’entreprise |
| M1813 | Intégrateur / Intégratrice logiciels métiers | M18 | Systèmes d’information et de télécommunication | M | Support à l’entreprise |
| M1804 | Ingénieur / Ingénieure télécoms | M18 | Systèmes d’information et de télécommunication | M | Support à l’entreprise |
| M1805 | Développeur / Développeuse web | M18 | Systèmes d’information et de télécommunication | M | Support à l’entreprise |
| M1806 | Product Owner | M18 | Systèmes d’information et de télécommunication | M | Support à l’entreprise |
| M1807 | Opérateur / Opératrice télécom aux armées | M18 | Systèmes d’information et de télécommunication | M | Support à l’entreprise |
| M1808 | Cartographe | M18 | Systèmes d’information et de télécommunication | M | Support à l’entreprise |
| M1809 | Météorologue | M18 | Systèmes d’information et de télécommunication | M | Support à l’entreprise |
| M1810 | Technicien / Technicienne informatique | M18 | Systèmes d’information et de télécommunication | M | Support à l’entreprise |
| M1401 | Enquêteur / Enquêtrice sondage | M14 | Organisation et études | M | Support à l’entreprise |
| M1803 | Directeur / Directrice des services informatiques -DSI- | M18 | Systèmes d’information et de télécommunication | M | Support à l’entreprise |
| M1802 | Ingénieur / Ingénieure système informatique | M18 | Systèmes d’information et de télécommunication | M | Support à l’entreprise |
| M1801 | Administrateur / Administratrice réseau informatique | M18 | Systèmes d’information et de télécommunication | M | Support à l’entreprise |

{{
config(
materialized='incremental',
unique_key='id'
)
}}
dbt run.dbt run
13:34:55 Running with dbt=1.8.3
13:34:56 Registered adapter: postgres=1.8.2
13:34:57 Found 7 models, 15 sources, 415 macros
13:34:57
13:34:59 Concurrency: 4 threads (target='dev')
13:34:59
13:34:59 1 of 7 START sql incremental model emploi.departement .......................... [RUN]
13:34:59 2 of 7 START sql incremental model emploi.dim_lieu ............................. [RUN]
13:34:59 3 of 7 START sql table model emploi.dim_lieu_activite .......................... [RUN]
13:34:59 4 of 7 START sql table model emploi.dim_naf .................................... [RUN]
13:35:00 4 of 7 OK created sql table model emploi.dim_naf ............................... [SELECT 732 in 0.20s]
13:35:00 5 of 7 START sql incremental model emploi.dim_rome ............................. [RUN]
13:35:00 1 of 7 OK created sql incremental model emploi.departement ..................... [INSERT 0 101 in 0.23s]
13:35:00 6 of 7 START sql incremental model emploi.fait_offre_emploi .................... [RUN]
13:35:00 5 of 7 OK created sql incremental model emploi.dim_rome ........................ [INSERT 0 609 in 0.11s]
13:35:00 7 of 7 START sql table model emploi.region ..................................... [RUN]
13:35:00 2 of 7 OK created sql incremental model emploi.dim_lieu ........................ [INSERT 0 34980 in 0.43s]
13:35:00 7 of 7 OK created sql table model emploi.region ................................ [SELECT 18 in 0.14s]
13:35:00 6 of 7 OK created sql incremental model emploi.fait_offre_emploi ............... [INSERT 0 31624 in 0.85s]
13:35:09 3 of 7 OK created sql table model emploi.dim_lieu_activite ..................... [SELECT 2561519 in 9.75s]
13:35:09
13:35:09 Finished running 3 table models, 4 incremental models in 0 hours 0 minutes and 12.34 seconds (12.34s).
13:35:09
13:35:09 Completed successfully
13:35:09
13:35:09 Done. PASS=7 WARN=0 ERROR=0 SKIP=0 TOTAL=7dbt docs generate. Cela génère un site statique qui rend son hébergement aisé, via GitHub Pages pour ce projet.dbt docs generate
11:42:22 Running with dbt=1.8.4
11:42:22 Registered adapter: postgres=1.8.2
11:42:22 Unable to do partial parsing because saved manifest not found. Starting full parse.
11:42:24 Found 2 models, 4 data tests, 417 macros
11:42:24
11:42:24 Concurrency: 4 threads (target='dev')
11:42:24
11:42:24 Building catalog
11:42:24 Catalog written to C:\privé\DE\entrepot-emploi-transformation\transformation\target\catalog.jsondbt docs servedbt docs serve
13:36:30 Running with dbt=1.8.3
Serving docs at 8080
To access from your browser, navigate to: http://localhost:8080
Press Ctrl+C to exit.
127.0.0.1 - - [03/Aug/2024 15:36:31] "GET / HTTP/1.1" 200 -
127.0.0.1 - - [03/Aug/2024 15:36:31] "GET /manifest.json?cb=1722692191330 HTTP/1.1" 200 -
127.0.0.1 - - [03/Aug/2024 15:36:31] "GET /catalog.json?cb=1722692191330 HTTP/1.1" 200 -
127.0.0.1 - - [03/Aug/2024 15:36:31] code 404, message File not found
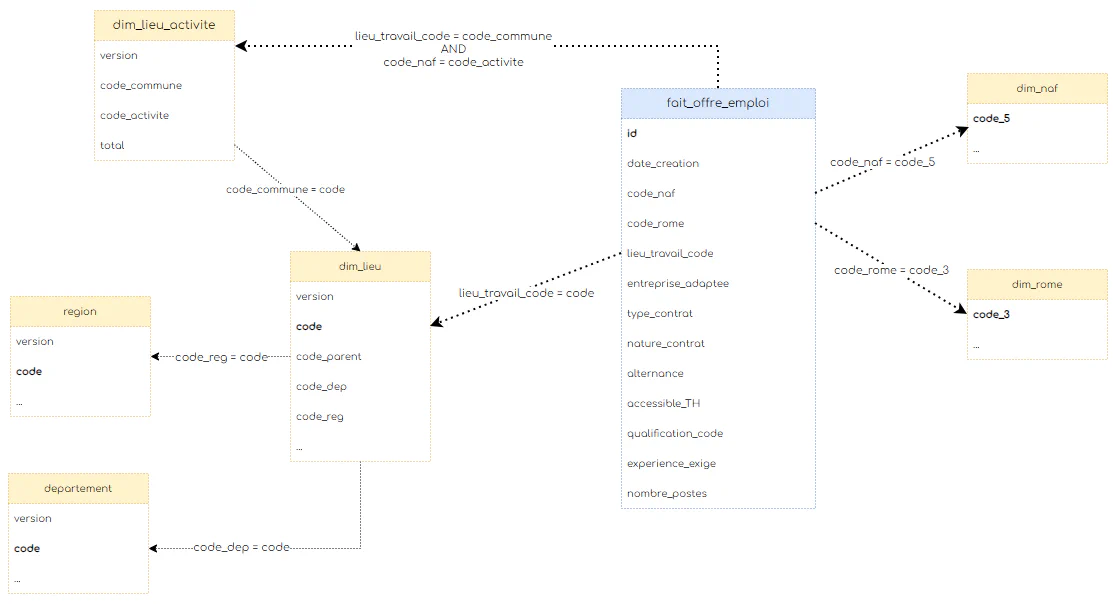
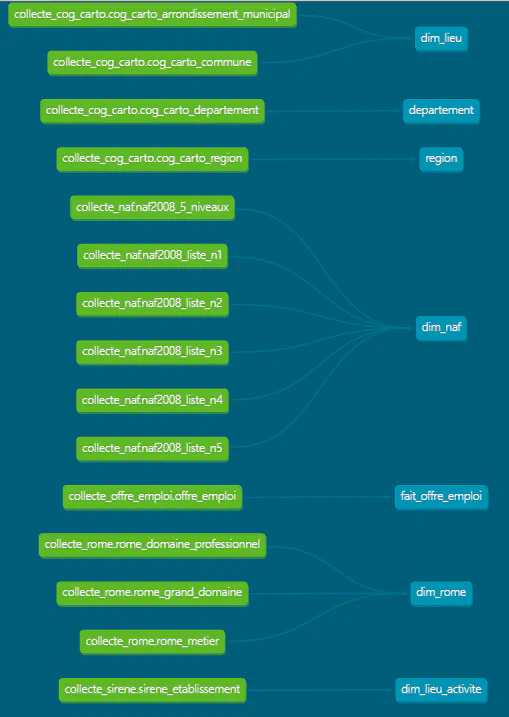
127.0.0.1 - - [03/Aug/2024 15:36:31] "GET /$%7Brequire('./assets/favicons/favicon.ico')%7D HTTP/1.1" 404 -Airflow via un BashOperator executant la commande dbt run --target prodLe modèle en étoile est une approche de modélisation de bases de données utilisée dans les entrepôts de données pour l’analyse des données. Il se caractérise par une table centrale appelée “table de faits” qui est reliée à plusieurs tables périphériques appelées “tables de dimensions”.
Table de fait: La table de faits contient les données quantitatives (mesures) que l’on souhaite analyser. Chaque enregistrement dans la table de faits représente une occurrence d’un événement ou une transaction. Ici, il s’agit de nos offres d’emploi.
Table de dimension: Les tables de dimensions contiennent des données descriptives qui fournissent des informations contextuelles sur les faits. Elles sont utilisées pour regrouper, filtrer, et segmenter les données de la table de faits. Ex: dim_lieu, dim_naf, dim_rome.
On parle parfois également d’une variante nommée modèle en flocons, lorsque certaines tables de dimensions sont liées à d’autres tables. Par exemple dans notre modèle, la table dim_lieu fait référence aux tables departement et région. A noter que les tables dim_lieu, departement et region auraient pu être dénormalisées dans une seules table afin de simplifier le modèle.